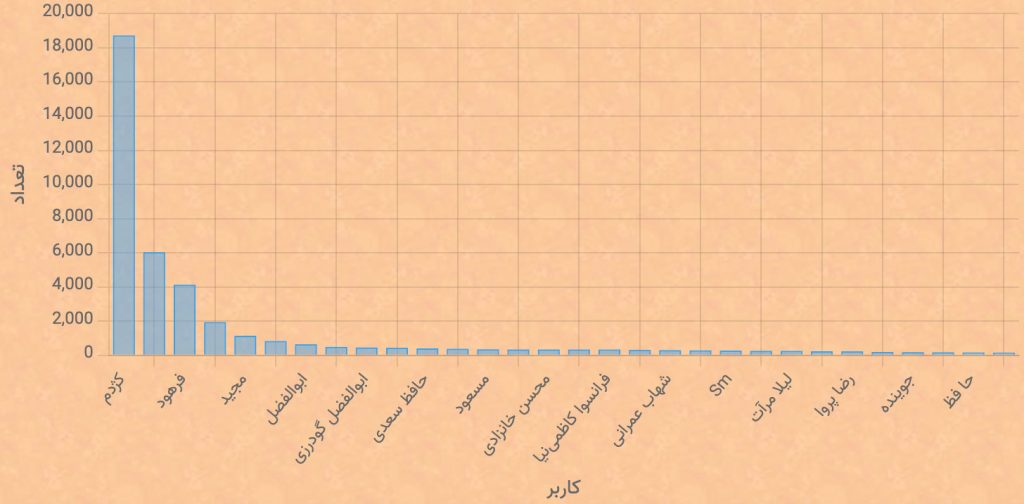
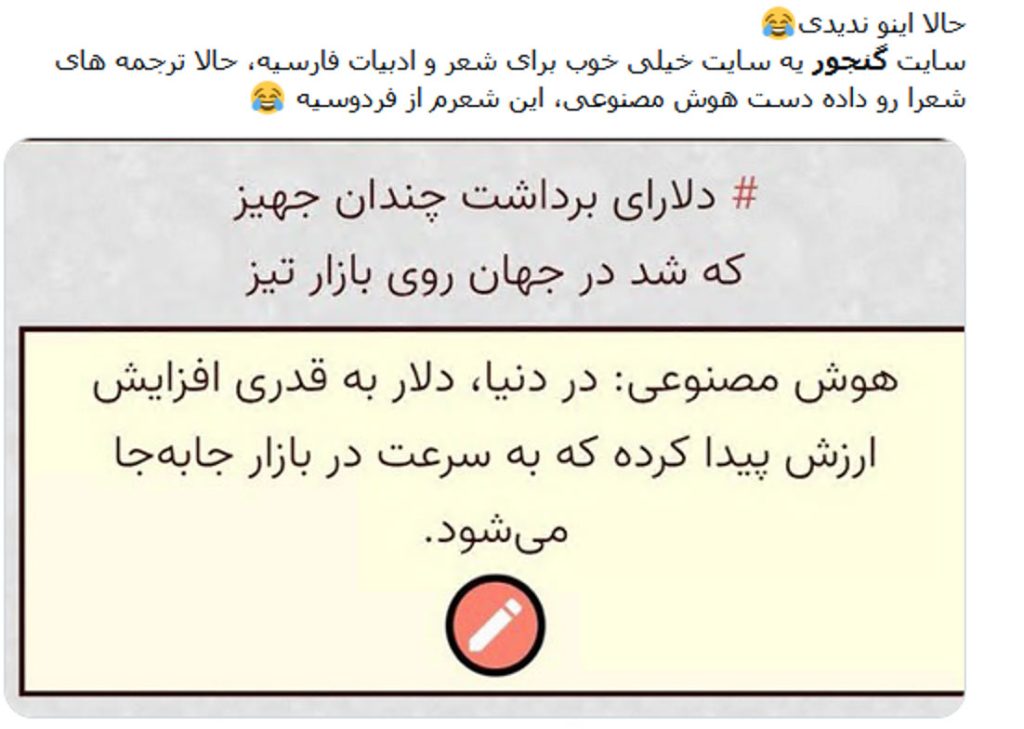
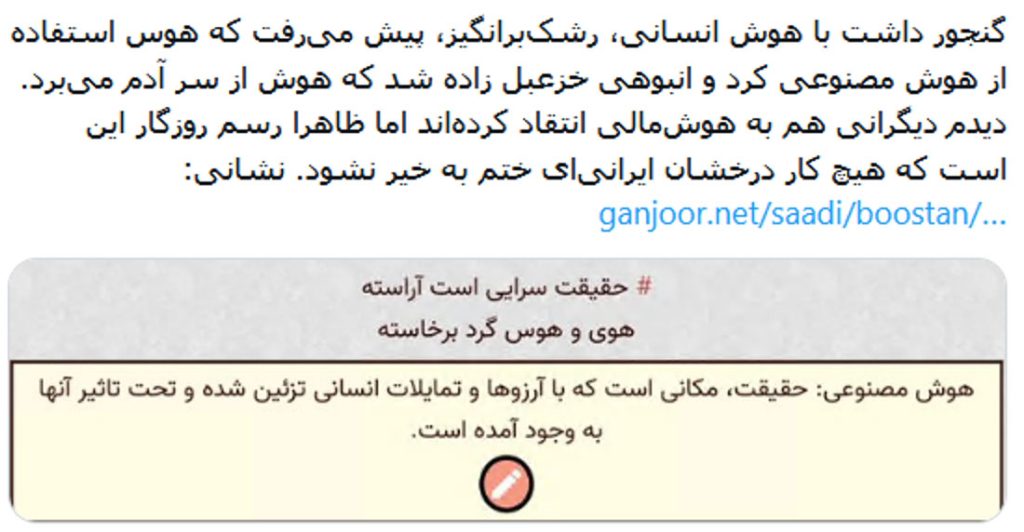
در ادامهٔ روند اختلال دسترسی به اینترنت طی روزهای گذشته، از دیروز و با قطع کامل اینترنت در ایران عملاً دسترسی به گنجور برای کاربران عمدهٔ آن که در ایران به سر میبرند غیرممکن شده است.
با توجه به این که این بار حتی دسترسی دیتاسنترهای داخلی به اینترنت نیز قطع شده است برای کاربران خارج از ایران نیز دسترسی به بعضی سرویسهای گنجور میسر نیست.
برای روشن شدن وضعیت لازم است توضیحاتی در مورد سرورهای گنجور ارائه شود:
۱. سرور اصلی گنجور یک سرور ویندوزی است که در خارج از ایران قرار دارد. علاوه بر دامنهٔ اصلی گنجور (ganjoor.net) بیشتر زیردامنههای مستقل عملیاتی گنجور مانند گنجینهٔ گنجور (museum.ganjoor.net)، محاسبهگر ابجد (abjad.ganjoor.net)، کتابخانهٔ گنجور (epub.ganjoor.net)، گنجور تاجیکی (tj.ganjoor.net)، کدهای گنجور (c.ganjoor.net)، پیشخان خوانشگران گنجور (gaudiopanel.ganjoor.net)، آوای گنجور (ava.ganjoor.net)، API گنجور (api.ganjoor.net) و تعدادی دیگر از زیردامنههای فعال گنجور روی این سرور قرار دارند و از این جهت با قطع اینترنت در ایران در دسترس نیستند.
۲. فایلهای گنجور اعم از تصاویر گنجینهٔ گنجور، خوانشها و همینطور فایلهای گنجور رومیزی و کتابخانهٔ گنجور به لحاظ حجم بالا و نیازمندی به ترافیک نامحدود روی یک سرویس میزبانی فایل مجزا در دیتاسنترهای داخل ایران نگهداری میشوند. از این جهت علیرغم آن که گنجینهٔ گنجور و خود گنجور در خارج از ایران در دسترسند به دلیل عدم دسترسی به فایلهای تصاویر و خوانشها برای کاربران خارج از ایران نیز این سرویسها خارج از دسترسند.
۳. تازههای گنجور (blog.ganjoor.net) و سایت گنجور رومیزی (dg.ganjoor.net) روی یک سرور لینوکسی در داخل ایران میزبانی میشوند. از این جهت داخل ایران قابل مشاهدهاند. در مورد گنجور رومیزی چون فایلهای برنامه روی سایت گیتهاب قرار دارند دریافت آن در شرایط قطع اینترنت در ایران امکانپذیر نیست اما مجموعههای قابل دریافت آن روی سرویس شمارهٔ ۲ میزبانی میشود که در داخل ایران در زمان قطعی اینترنت در دسترس است.
۴. نسکبان (naskban.ir) روی یک سرور ویندوزی در داخل ایران که به منظور پشتیبان فایلهای گنجور تهیه شده میزبانی میشود. فایلها و تصاویر آن نیز روی سرویس شمارهٔ ۲ نگهداری میشود. از این جهت در هنگام قطع اینترنت روی اینترانت داخلی ایران (برای کاربرانی که پیشتر به آن مراجه کردهاند و اسکریپتهای آن روی دستگاهشان کش (cache) شده باشد) در دسترس است.
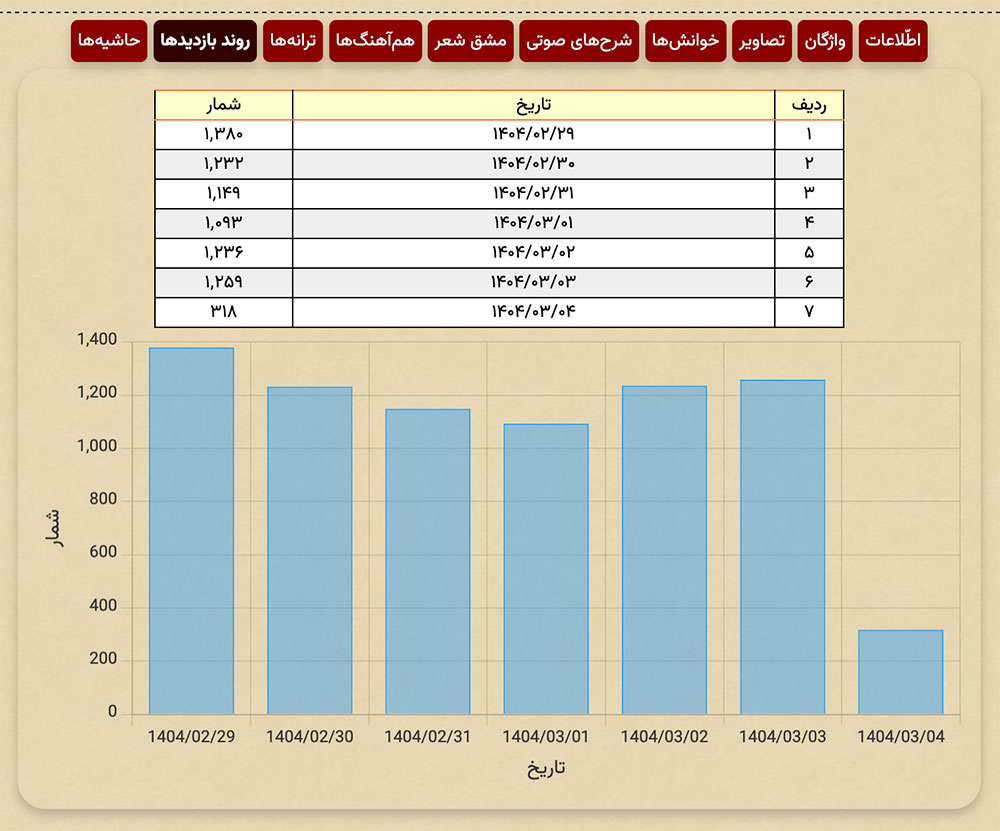
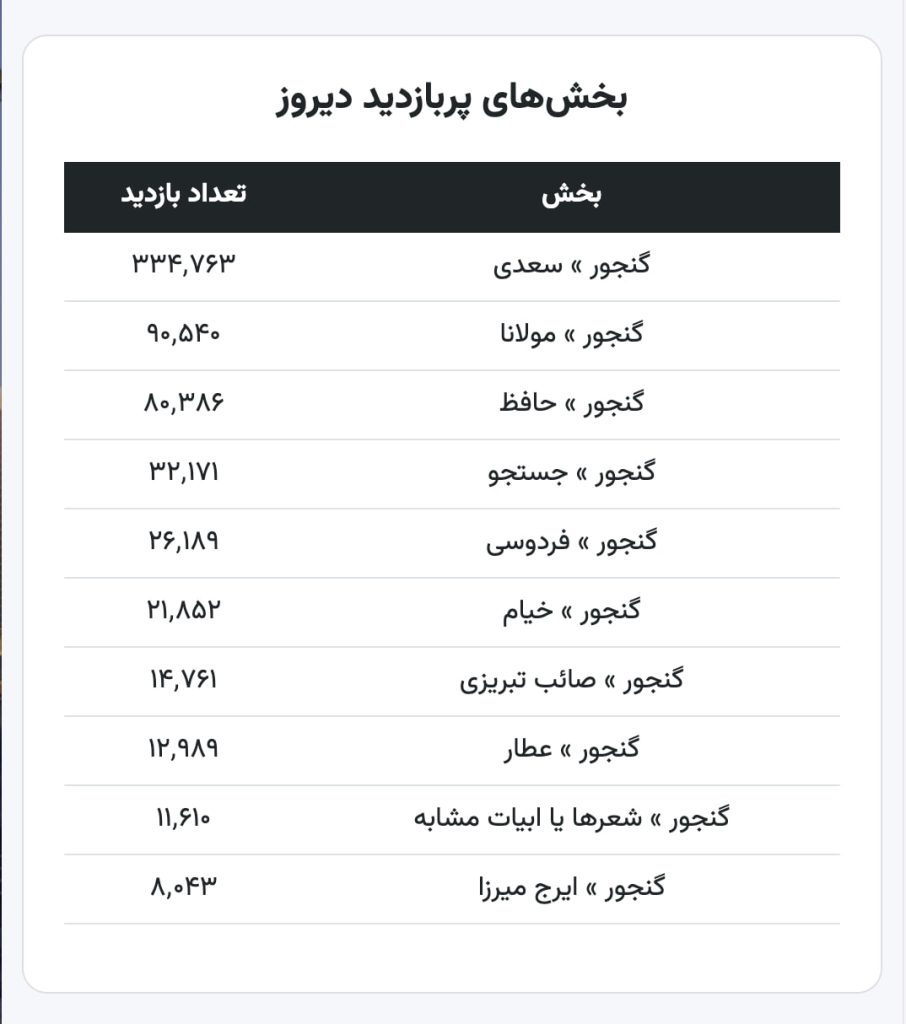
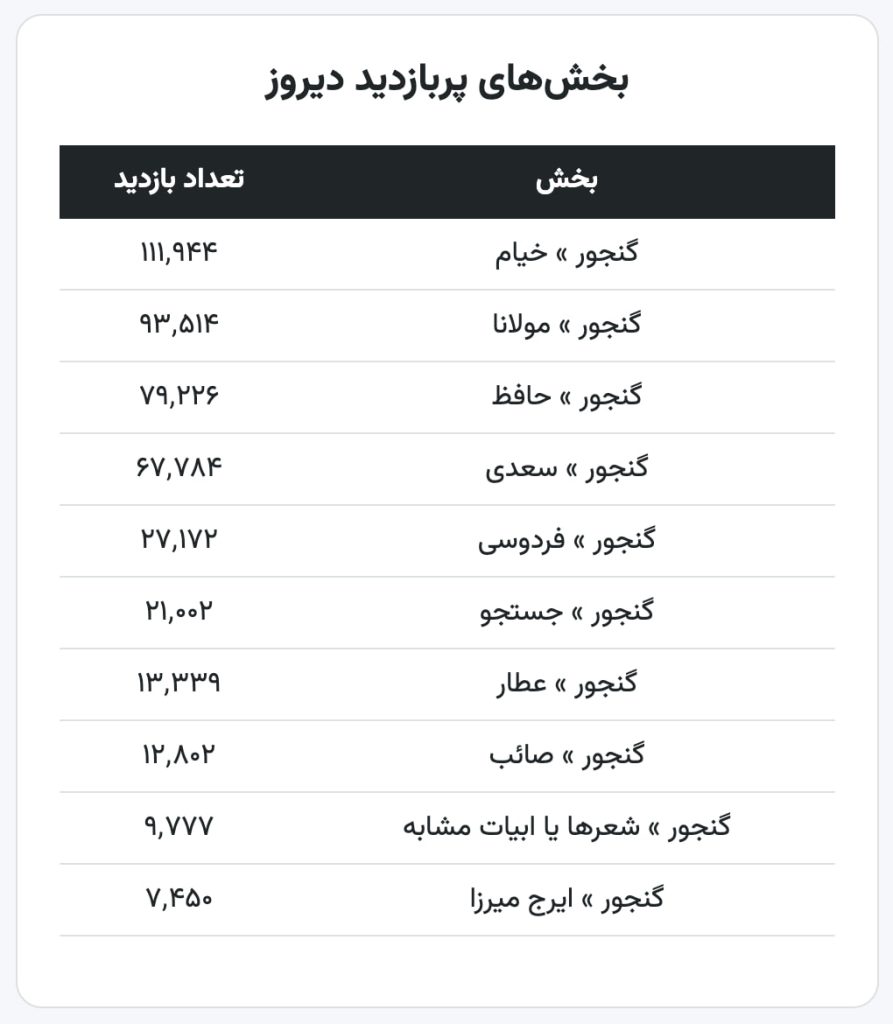
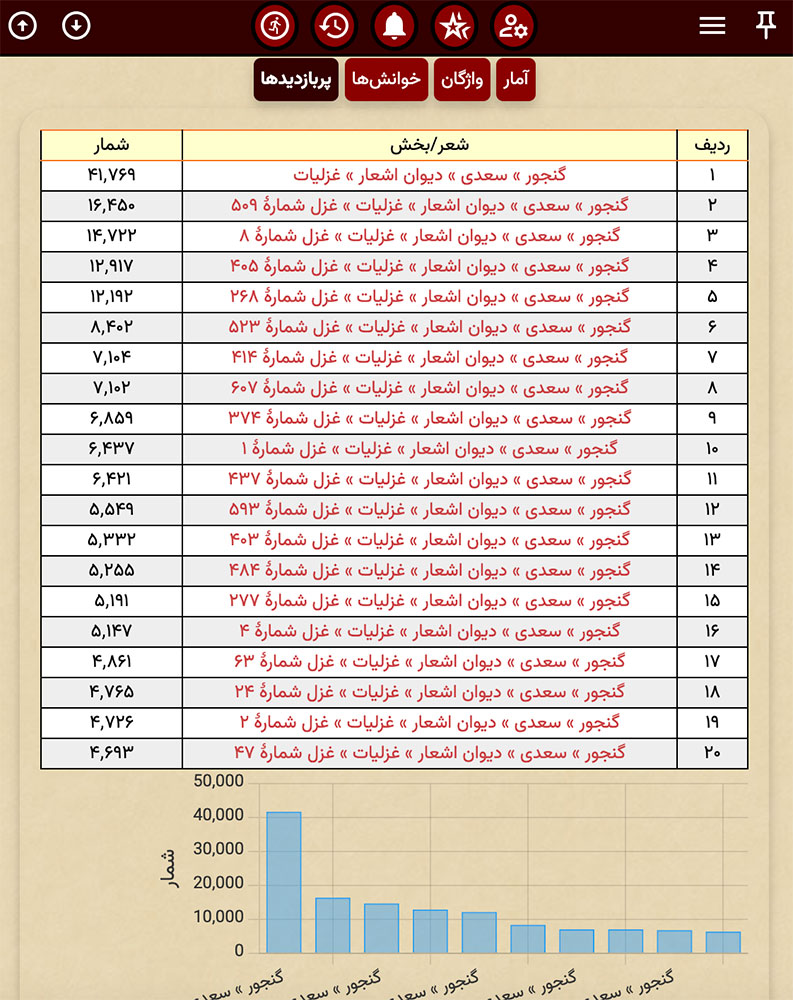
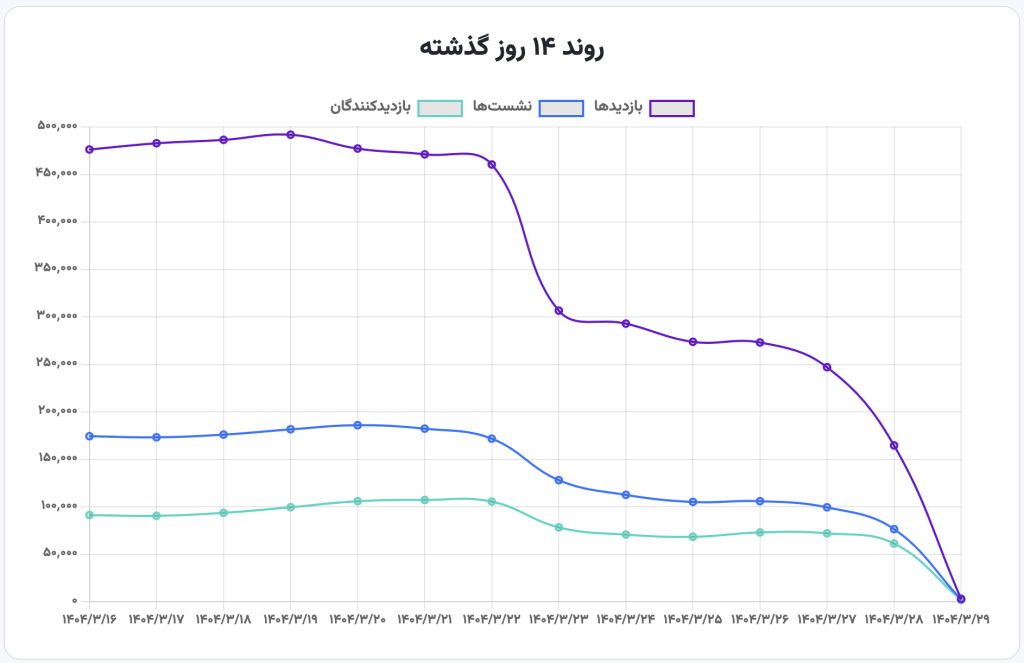
۵. سرویس آمارگیری کنتور (kntr.ir) که اخیراً برای رصد آمار بازدیدهای گنجور راهاندازی شده روی سرور ردیف ۴ (نسکبان) میزبانی میشود. از این جهت علیرغم آن که داخل ایران در دسترس است به دلیل عدم دسترسی به آن در خارج از ایران قادر به جمعآوری آمار گنجور نیست و علیرغم این که گنجور روی اینترنت در دسترس است و طبق معمول درصد قابل توجهی از بازدیدکنندگان آن در خارج از ایران قرار دارند آمارهای این بازدیدکنندگان را در زمان قطعی اینترنت در ایران نمیتواند جمعآوری کند. ضمناً بعضی امکانات اخیر مرتباط با آن در گنجور (این و این) به لحاظ عدم دسترسی سرور گنجور به آن در گنجور از کار میافتند.
۶. نکتهٔ نهایی آن که گنجور برای سرویس DNS از کلاودفلر استفاده میکند که به نظر میرسد اخیراً روی سرویسدهندههای داخلی ایران دچار اختلالات عمدی شده و اختلالات مربوط به پیش از قطع کامل اینترنت گنجور (کاهش تا ۲۵۰هزار بازدید روزانهٔ آن) میتواند ناشی از آن باشد. ضمناً تقریباً همهٔ سایتهای گنجور برای نمایش صحیح نیازمند دسترسی به منابعی مانند اسکریپتها و فونتها و استایلشیتهای در دسترس روی CDNهای بینالمللی هستند و از این جهت نمایش آنهایی نیز که روی اینترانت داخلی قرار دارند برای بازدیدکنندگانی که پیشتر مراجعهای به این سایتها نداشته باشند و این اطلاعات روی آنها کش (cache) نشده باشد به مشکل برمیخورد.
تصمیم به میزبانی سرور اصلی گنجور در خارج از ایران با این ایده که گنجور جزئی از اینترنت و نه یک اینترانت بستهٔ داخلی باشد گرفته شده. در مورد انتخاب سرورها و سرویسهای داخلی برای سرویسهای جانبی نیز فاکتور هزینه دخیل بوده است.