یکی از کارکردهای آمار بسامد واژگان مقایسهٔ فراوانی کاربرد یک واژه بین سخنوران مختلف است. اما این کار نیازمند مراجعه به صفحات مختلف و نگه داشتن آمارهای هر صفحه است که زمانبر و پیچیده است.
برای آسانسازی این کار به صفحهٔ جستجو امکانی اضافه شده که با آن میتوان میزان فراوانی کاربرد یک واژه را میان سخنوران و بخشهای مختلف مشاهده و مقایسه کرد. این امکان به طور پیشفرض پایین صفحات جستجو و مطابق تصویر بعد در دسترس است:

نتیجه:
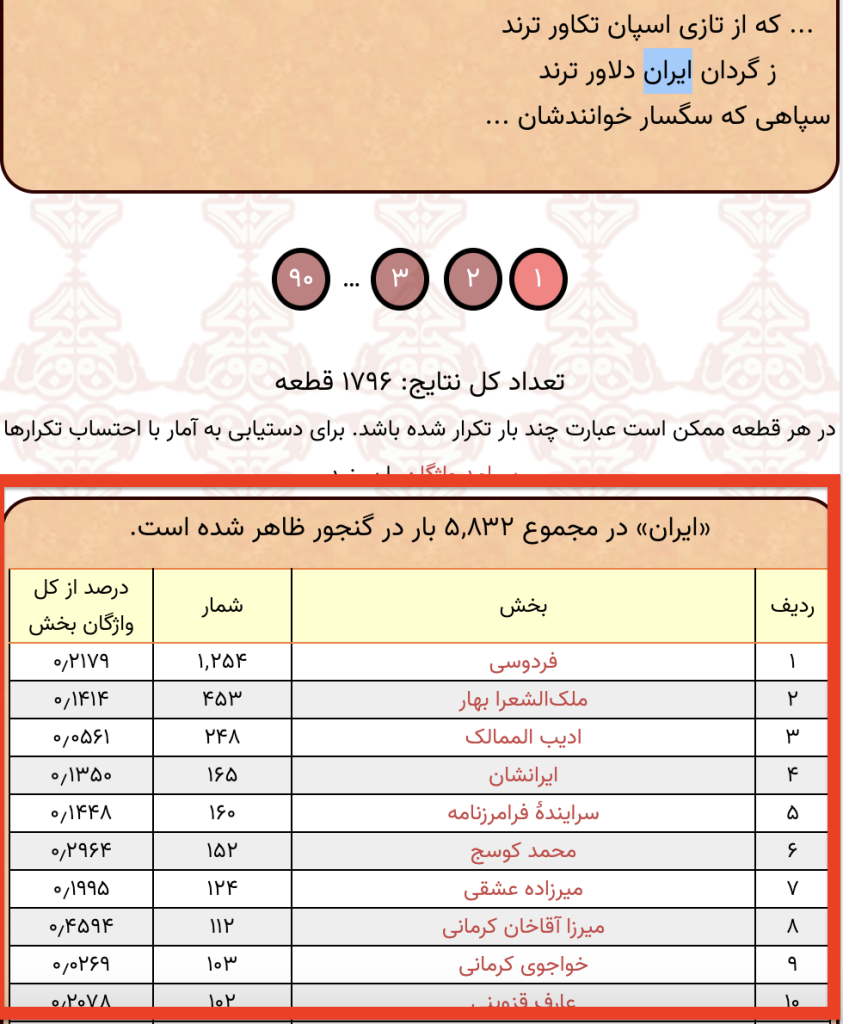
در صورتی که هر کدام از پیوندهای ستون بخش را دنبال کنید میتوانید بسامد آن واژه را به تفکیک زیربخشها ببینید:
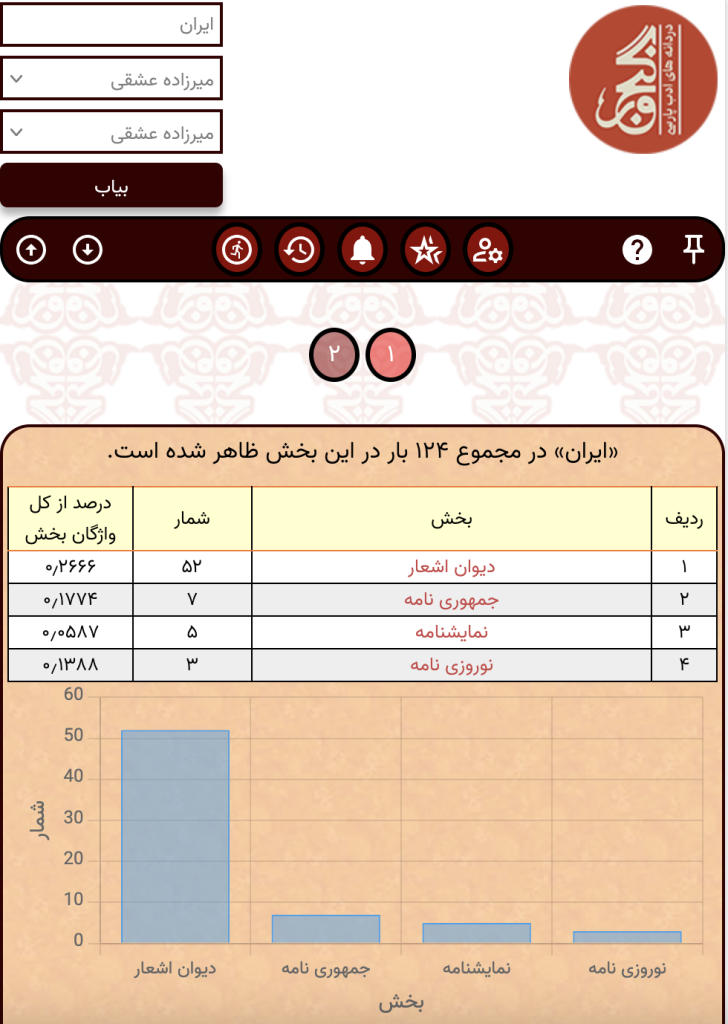
و این کار را برای زیربخشها تکرار کنید.
در صفحات جستجویی که از طریق همین بخش یا بخشهای بسامد واژگان در صفحات معرفی سخنوران یا زیربخشهای آثار آنها و یا از طریق صفحهٔ آمار باز میشوند این قسمت به طور پیشفرض بالای صفحه قرار دارد و با باز شدن صفحه به طور خودکار محاسبه میشود.
غیر از این، آقای حسین سامانی چند روز پیش مشکلی را در محاسبهٔ بسامد واژگان برای بخشهای دارای عمق زیاد از زیربخشها گزارش کردند که این مشکل هماکنون از لحاظ نرمافزاری حل شده، منتهی تصحیح اعداد نیازمند شمارش مجدد واژگان است که آن هم در دست انجام است.